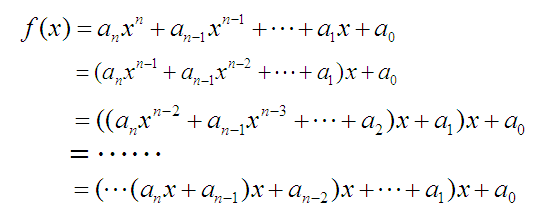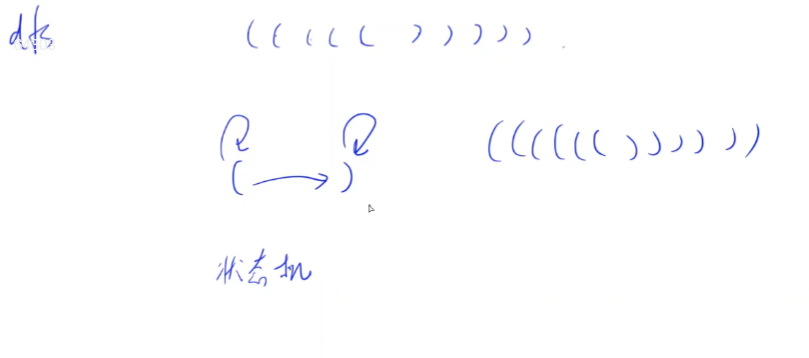#include<iostream> #include<vector> #include<algorithm> usingnamespacestd; #define fi first #define se second typedefpair<int,int> PII; constint N = 55; char g[N][N]; vector<PII> points[2]; int dx[] = {0,0,1,-1},dy[] = {1,-1,0,0}; int n,m;
voiddfs(int x,int y,vector<PII> &p){ g[x][y] = '.'; p.push_back({x,y}); for (int i = 0;i < 4;i ++){ int a = x+dx[i],b = y+dy[i]; if (a >= 0 && a < n && b >= 0 && b < m && g[a][b] == 'X') dfs(a,b,p); } }
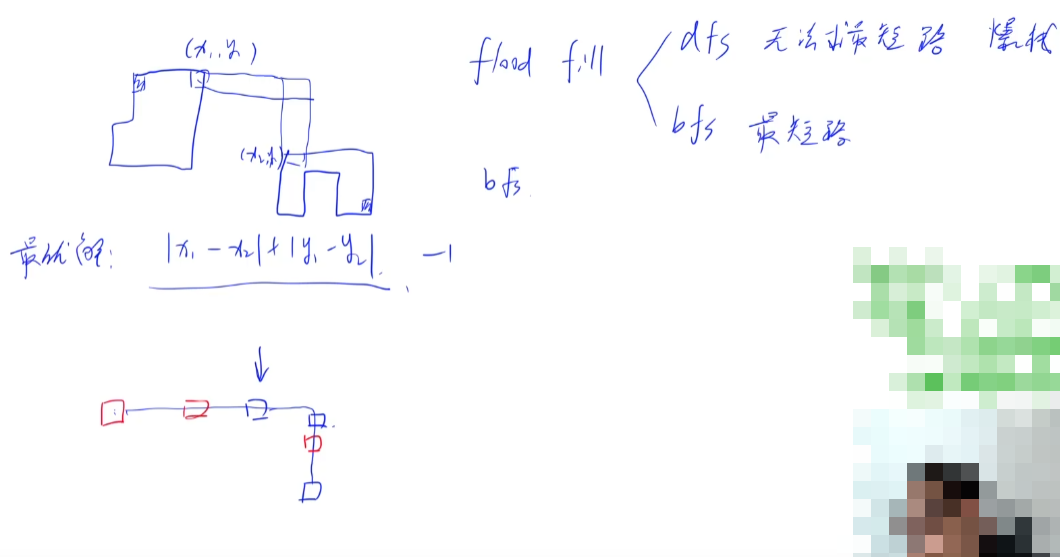
intmain(){ cin >> n >> m; for (int i = 0;i < n;i ++) cin >> g[i]; for (int i = 0,k = 0;i < n;i ++) for (int j = 0;j < m;j ++) if (g[i][j] == 'X') dfs(i,j,points[k++]); int res = 1e9; for (auto &a : points[0]) for (auto &b : points[1]) res = min(res,abs(a.fi-b.fi)+abs(a.se-b.se) - 1); // 距离记得-1 cout << res << '\n'; return0; }
#include<iostream> #include<algorithm> #include<cstring> #include<deque> usingnamespacestd; typedefpair<int,int> PII; #define fi first #define se second constint N = 1010; int dist[N][N]; bool st[N][N],g[N][N]; int n,x,y; int dx[] = {0,0,1,-1},dy[] = {1,-1,0,0};
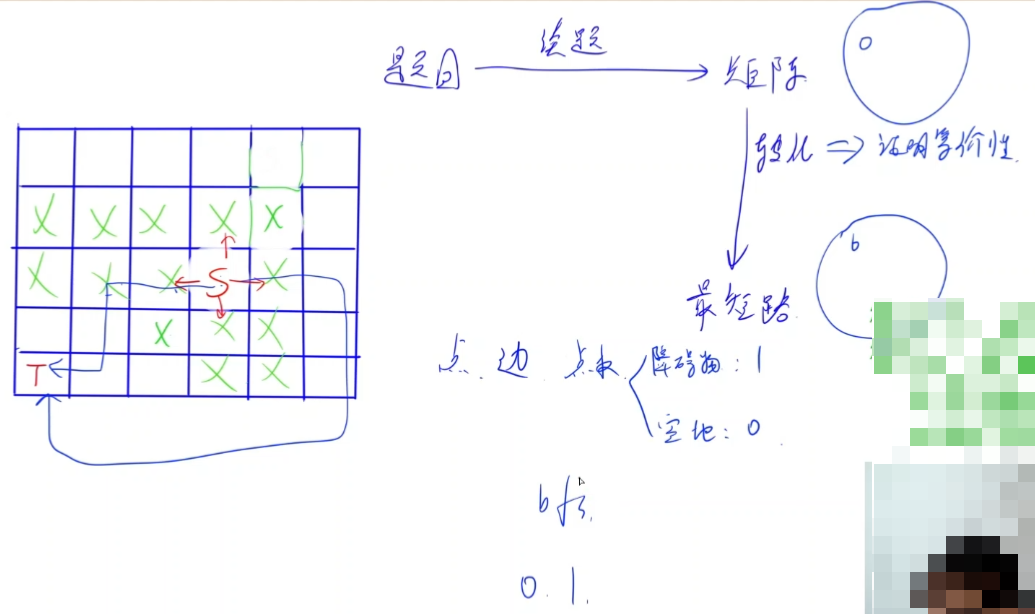
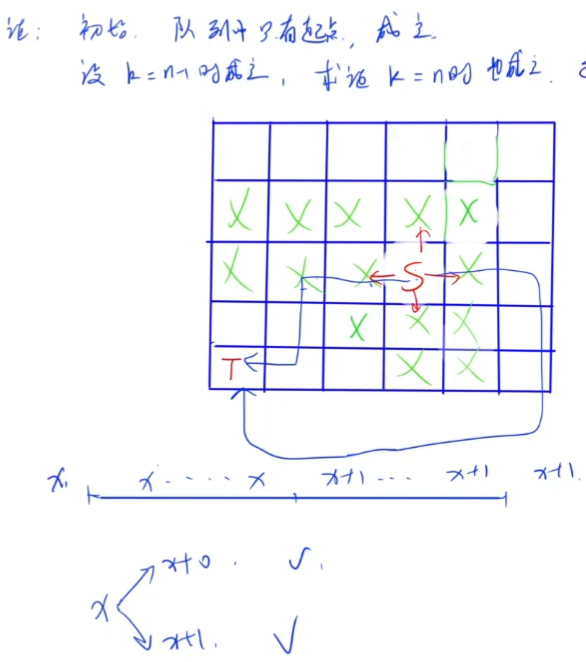
intbfs(int sx,int sy){ // 双端队列广搜 deque<PII> q; q.push_back({sx,sy}); memset(dist,0x3f,sizeof dist); dist[sx][sy] = 0; // 搜索一条从sx,sy走到0,0的带权最短路 while (q.size()){ auto t = q.front(); q.pop_front(); int x = t.fi,y = t.se; if (st[x][y]) continue; // 出队判重优化 st[x][y] = true; if (!x && !y) break; // 0,0第一次出现的时候是最短路 for (int i = 0;i < 4;i ++){ int a = x+dx[i],b = y+dy[i]; if (a >= 0 && a <= 1001 && b >= 0 && b <= 1001){ int w = 0; if (g[a][b]) w = 1; // 有干草堆则边权为1,否则为0 if (dist[a][b] > dist[x][y] + w){ dist[a][b] = dist[x][y] + w; if (!w) q.push_front({a,b}); // w为0加入队头 else q.push_back({a,b}); // 否则加入队尾 } } } } return dist[0][0]; }
intmain(){ cin >> n >> x >> y; int a,b; while (n--){ cin >> a >> b; g[a][b] = true; // 有干草堆则为true } cout << bfs(x,y) << '\n'; return0; }
#include<iostream> #include<algorithm> usingnamespacestd; constint N = 1e5+5; typedefpair<int,int> PII; #define fi first #define se second int n,h[N]; PII q[N];
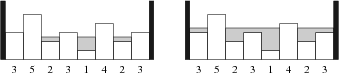
intmain(){ cin >> n; for (int i = 1;i <= n;i ++) cin >> h[i]; n = unique(h+1,h+n+1) - (h+1); // 去重,除去相邻的高度相等的一段田 h[n+1] = 0; // 也默认了h[0] = 0,这两个高度在判断时都会用到 for (int i = 1;i <= n;i ++) q[i] = {h[i],i}; sort(q+1,q+n+1); // 对高度排序 int res = 1,cnt = 1; for (int i = 1;i <= n;i ++){ int y = q[i].se; if (h[y-1] > h[y] && h[y+1] > h[y]) cnt ++; // 两边高中间低 elseif (h[y-1] < h[y] && h[y+1] < h[y]) cnt --; // 中间高两边低 // 两个非连续的高度相等的田需要同时更新res if (q[i].fi != q[i+1].fi) res = max(res,cnt); } cout << res; return0; }
#include<iostream> usingnamespacestd; int n,ans; bool st[10][10]; char g[10][10]; int dx[] = {0,0,1,-1},dy[] = {1,-1,0,0};
voiddfs(int x,int y,int l,int r){ st[x][y] = true; if (l == r){ ans = max(ans,l+r); st[x][y] = false; // 回溯前先将st复原 return; } for (int i = 0;i < 4;i ++){ int a = x + dx[i],b = y + dy[i]; if (a >= 0 && a < n && b >= 0 && b < n && !st[a][b]){ if (g[x][y] ==')' && g[a][b] == '(') continue; // 排除不合法搜索状态 if (g[a][b] == '(') dfs(a,b,l+1,r); else dfs(a,b,l,r+1); } } st[x][y] = false; // 回溯前先将st复原 }
intmain(){ cin >> n; for (int i = 0;i < n;i ++) for (int j = 0;j < n;j ++) cin >> g[i][j]; if (g[0][0] == '(') dfs(0,0,1,0); cout << ans; return0; }