#include<iostream> #include<algorithm> usingnamespacestd; constint N = 1e5+5; int a[N],b[N]; // 在b中查找值等于x的下标,找到返回true,下标为l,否则返回false boolsearch(int &l,int &r,int x){// l和r传引用,需要修改值并输出 while (l < r){ int mid = l + r >> 1; if (b[mid] >= x) r = mid; else l = mid + 1; } return b[l] == x; }
intmain(){ ios::sync_with_stdio(false); cin.tie(0); cout.tie(0); int n,m,x; cin >> n >> m >> x; for (int i = 0;i < n;i ++) cin >> a[i]; for (int i = 0;i < m;i ++) cin >> b[i]; // sort(a,a+n);题目说了是2个升序的数组 // sort(b,b+m); for (int i = 0;i < n;i ++){ int t = x - a[i]; int l = 0,r = m - 1; if (search(l,r,t)) cout << i << " " << l; } return0; }
算法2:双指针。时间复杂度:O(n*logn)。
先考虑暴力做法:
1 2 3
for (int i = 0;i < n;i ++) for(int j = 0;j < m;j ++) if (a[i] + b[j] == x) cout << i << ' ' << j;
// 参考Bug-Free同学后的题解 #include<iostream> usingnamespacestd; #define IOS \ ios::sync_with_stdio(false); \ cin.tie(0); \ cout.tie(0) constint N = 1e5+5; int n,m; int a[N],b[N];
intmain(){ IOS; cin >> n >> m; for (int i = 0;i < n;i ++) cin >> a[i]; for (int i = 0;i < m;i ++) cin >> b[i]; int j = 0;// j放在循环外面,判断要用 // i指针遍历b数组,j指针遍历a数组 for (int i = 0; i < m; i++) { if (j < n && a[j] == b[i]) j ++;// 和KMP类似,这里用if,不用while }
if (j == n) {// j指针走到a数组末尾说明找到子序列 cout << "Yes" << endl; } else { cout << "No" << endl; } return0; } // y总题解 int i = 0,j = 0; while (i < n && j < m){ if (a[i] == b[j]) i ++;// 匹配成功i指针再往后走 j ++;// 不管匹配是否成功j指针都必须往后走 }
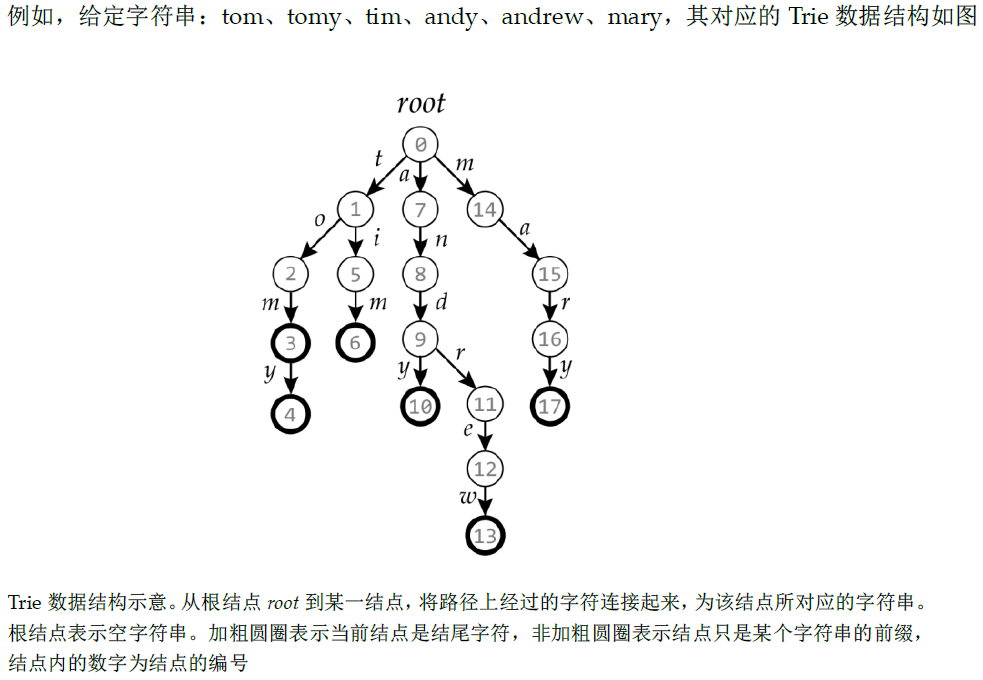
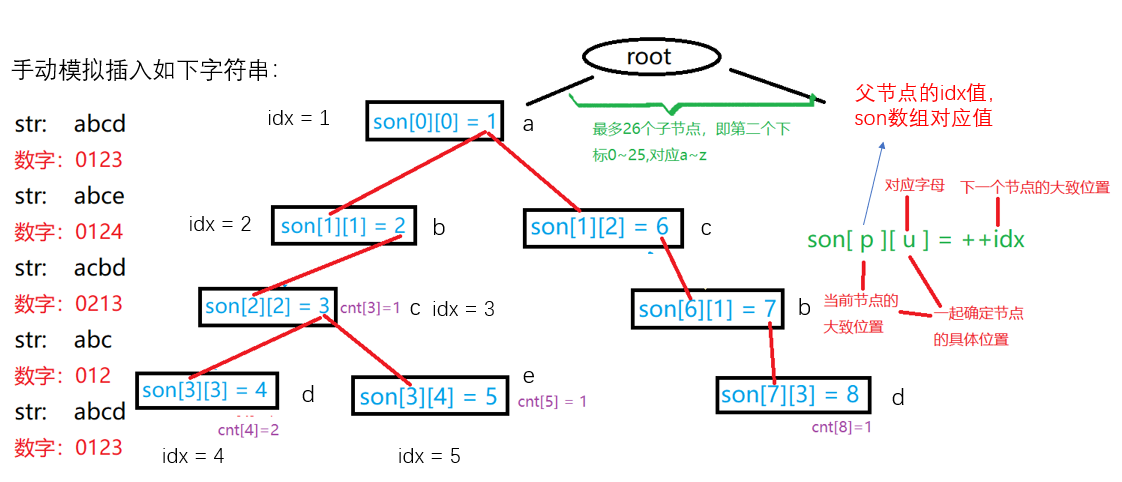
voidinsert(char* str){ int p = 0;// 类似指针,指向当前节点 for (int i = 0; str[i]; i ++){ int u = str[i] - 'a';// 将小写字母转换成整数u方便下标处理 if (!son[p][u]) son[p][u] = ++ idx;// 没有该子节点就创建一个 // 此时的p就是str中最后一个字符对应的trie树的位置idx p = son[p][u];// 走到p的子节点 } cnt[p] ++; }
intquery(char* str){ int p = 0; for (int i = 0; str[i];i ++){ int u = str[i] - 'a'; if (!son[p][u]) return0;// 该节点不存在,即该字符串不存在 p = son[p][u]; } return cnt[p];// 返回字符串出现的次数 }
intmain(){ IOS; int n; cin >> n; char op[2];// 注意开到2,读入的是"I\0" while (n--){ cin >> op >> str; if (op[0] == 'I') insert(str); elsecout << query(str) << '\n'; } return0; }