第一周 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Farmer John 的奶牛正在 mooZ 视频会议平台上举行每日集会。 她们发明了一个简单的数字游戏,为会议增添一些乐趣。 Elsie 有三个正整数 A、B 和 C (A≤B≤C)。 这些数字是保密的,她不会直接透露给她的姐妹 Bessie。 她告诉 Bessie 七个范围在 1 …109 之间的整数(不一定各不相同),并宣称这是 A、B、C、A+B、B+C、C+A 和 A+B+C 的某种排列。 给定这七个整数,请帮助 Bessie 求出 A、B 和 C。 可以证明,答案是唯一的。 输入格式 输入一行,包含七个空格分隔的整数。 输出格式 输出 A、B 和 C,用空格分隔。 数据范围 1 ≤所有输入的整数≤10 ^9 输入样例: 2 2 11 4 9 7 9 输出样例: 2 2 7
本题比较简单,小学数学了属于是。
题解一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <algorithm> using namespace std ;const int N = 8 ;int q[N];int main () for (int i = 0 ;i < 7 ;i ++) cin >> q[i]; sort(q,q + 7 ); int t = q[6 ] - q[0 ]; for (int i = 1 ,j = 5 ;i < j;){ if (q[i] + q[j] > t) j --; else if (q[i] + q[j] < t) i ++; else { cout << q[0 ] << ' ' << q[i] << ' ' << q[j]; break ; } } return 0 ; }
题解二:
解题方法:
why?
然后 A+B+C 是最大的,我们可以直接通过 A 和 B 求出 C,完事了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;int a[10 ];int main () for (int i = 1 ; i <= 7 ; i ++ ) cin >> a[i]; sort(a + 1 , a + 8 ); cout << a[1 ] << " " << a[2 ] << " " << a[7 ] - a[1 ] - a[2 ] << endl ; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 一个鲜为人知的事实是,奶牛拥有自己的文字:「牛文」。 牛文由 26 个字母 a 到 z 组成,但是当奶牛说牛文时,可能与我们所熟悉的 abcdefghijklmnopqrstuvwxyz 不同,她会按某种特定的顺序排列字母。 为了打发时间,奶牛 Bessie 在反复哼唱牛文字母歌,而 Farmer John 好奇她唱了多少遍。 给定一个小写字母组成的字符串,为 Farmer John 听到 Bessie 唱的字母,计算 Bessie 至少唱了几遍完整的牛文字母歌,使得 Farmer John 能够听到给定的字符串。 Farmer John 并不始终注意 Bessie 所唱的内容,所以他可能会漏听 Bessie 唱过的一些字母。 给定的字符串仅包含他记得他所听到的字母。 输入格式 输入的第一行包含 26 个小写字母,为a到z的牛文字母表顺序。 下一行包含一个小写字母组成的字符串,为 Farmer John 听到 Bessie 唱的字母。 输出格式 输出 Bessie 所唱的完整的牛文字母歌的最小次数。 数据范围 字符串的长度不小于 1 且不大于 1000 。 输入样例: abcdefghijklmnopqrstuvwxyz mood 输出样例: 3 样例解释 在这个样例中,牛文字母表与日常的字母表的排列一致。 Bessie 至少唱了三遍牛文字母歌。 有可能 Bessie 只唱了三遍牛文字母歌,而 Farmer John 听到了以下被标记为大写的字母。 abcdefghijklMnOpqrstuvwxyz abcdefghijklmnOpqrstuvwxyz abcDefghijklmnopqrstuvwxyz
不会了。考察贪心算法。
问题也就是至少几个字母表的序列包含给定字符串这个子序列。
将字母表映射到一个数字序列:0~25,每个字母对应一个数字。
构造一个贪心解,将给定字符串分解为上升的子串,比如2,4和3,7和1,5,7。
可以证明至少需要的字母表的个数也就等于上升的子串的个数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> #include <algorithm> using namespace std ;int p[26 ];int main () string alphabet,str; cin >> alphabet >> str; for (int i = 0 ;i < 26 ;i ++) p[alphabet[i] - 'a' ] = i; int res = 1 ; for (int i = 1 ;i < str.size();i ++){ if (p[str[i] - 'a' ] <= p[str[i-1 ] - 'a' ]) res ++; } cout << res << '\n' ; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 Farmer John 的奶牛们得知最近正在庆祝牛年的到来时十分兴奋。 牛年总是奶牛们的最爱。 我们知道,中国历法中每一年所对应的生肖遵循 12 年的周期:Ox, Tiger, Rabbit, Dragon, Snake, Horse, Goat, Monkey, Rooster, Dog, Pig, Rat(牛、虎、兔、龙、蛇、马、羊、猴、鸡、狗、猪、鼠),然后回到牛。 奶牛 Bessie 自豪地说她是在许多年前的一个牛年出生的。 她的朋友 Elsie 想要知道她与 Bessie 出生相差多少年,并且希望你能够通过查看农场上若干奶牛出生年份之间的关系来帮助她推算。 输入格式 输入的第一行包含一个整数 N。 以下 N 行每行包含一个 8 个单词的短语,指定了两头奶牛的出生年份之间的关系,格式为 Mildred born in previous Dragon year from Bessie(Mildred 在 Bessie 出生的前一个龙年出生),或 Mildred born in next Dragon year from Bessie(Mildred 在 Bessie 出生的后一个龙年出生)。 最后一个单词是农场上某一头奶牛的名字,为 “Bessie” 或一头已经在之前的输入中出现过的奶牛。 第一个单词是农场上某一头奶牛的名字,不为 “Bessie” 且未在之前的输入中出现过。 所有的奶牛名字不超过 10 个字符,且仅包含字符 a..z 或 A..Z。 第 5 个单词是上述十二生肖之一。 第 4 个单词是 previous(之前)或 next(之后)之一。 例如,如果短语为 Mildred born in previous Dragon year from Bessie,则 Mildred 的出生年份为最为接近且严格处于 Bessie 的出生年份之前(不等于)的龙年。 输出格式 输出 Bessie 和 Elsie 的出生年份之间相差的年数。输入保证可以通过给定的信息求出结果。 数据范围 1 ≤N≤100 输入样例: 4 Mildred born in previous Dragon year from Bessie Gretta born in previous Monkey year from Mildred Elsie born in next Ox year from Gretta Paulina born in next Dog year from Bessie 输出样例: 12 样例解释 在以上的输入中, Elsie 在 Bessie 之前 12 年出生。 Mildred 在 Bessie 之前 9 年出生。 Gretta 在 Bessie 之前 17 年出生。 Paulina 在 Bessie 之后 9 年出生。
又不会。有难度。
我们知道Bessie是在某个牛年出生的,但是不知道具体年份(不影响),不妨将它看作元年(类比Jesus出生),其他的牛出生年份都可以确定和Bessie的相对距离。
本题的关键就在于如何确定两头牛相差的年份,可以枚举十二生肖,也可以利用同余算出来。
如何计算呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <string> #include <algorithm> #include <unordered_map> using namespace std ;unordered_map <string ,int > table{ {"Ox" ,0 },{"Tiger" ,1 },{"Rabbit" ,2 },{"Dragon" ,3 }, {"Snake" ,4 },{"Horse" ,5 },{"Goat" ,6 },{"Monkey" ,7 }, {"Rooster" ,8 },{"Dog" ,9 },{"Pig" ,10 },{"Rat" ,11 } }; int main () unordered_map <string ,int > p; p["Bessie" ] = 0 ; int n; string str[8 ]; cin >> n; while (n--){ for (int i = 0 ;i < 8 ;i ++) cin >> str[i]; if (str[3 ] == "previous" ){ int x = p[str[7 ]],y = table[str[4 ]]; int r = ((x - y) % 12 + 12 ) % 12 ; if (!r) r = 12 ; p[str[0 ]] = x - r; }else { int x = p[str[7 ]],y = table[str[4 ]]; int r = ((y - x) % 12 + 12 ) % 12 ; if (!r) r = 12 ; p[str[0 ]] = x + r; } } cout << abs (p["Elsie" ]) << '\n' ; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 由于对计算机科学的热爱,以及有朝一日成为 「Bessie 博士」的诱惑,奶牛 Bessie 开始攻读计算机科学博士学位。 经过一段时间的学术研究,她已经发表了 N 篇论文,并且她的第 i 篇论文得到了来自其他研究文献的 ci 次引用。 Bessie 听说学术成就可以用 h 指数来衡量。 h 指数等于使得研究员有至少 h 篇引用次数不少于 h 的论文的最大整数 h。 例如,如果一名研究员有 4 篇论文,引用次数分别为 (1 ,100 ,2 ,3 ),则 h 指数为 2 ,然而若引用次数为 (1 ,100 ,3 ,3 ) 则 h 指数将会是 3 。 为了提升她的 h 指数,Bessie 计划写一篇综述,并引用一些她曾经写过的论文。 由于页数限制,她至多可以在这篇综述中引用 L 篇论文,并且她只能引用每篇她的论文至多一次。 请帮助 Bessie 求出在写完这篇综述后她可以达到的最大 h 指数。 注意 Bessie 的导师可能会告知她纯粹为了提升 h 指数而写综述存在违反学术道德的嫌疑;我们不建议其他学者模仿 Bessie 的行为。 输入格式 输入的第一行包含 N 和 L。 第二行包含 N 个空格分隔的整数 c1,…,cN。 输出格式 输出写完综述后 Bessie 可以达到的最大 h 指数。 数据范围 1 ≤N≤10 ^5 ,0 ≤ci≤10 ^5 ,0 ≤L≤10 ^5 输入样例1 : 4 0 1 100 2 3 输出样例1 : 2 样例1 解释 Bessie 不能引用任何她曾经写过的论文。上文中提到,(1 ,100 ,2 ,3 ) 的 h 指数为 2 。 输入样例2 : 4 1 1 100 2 3 输出样例2 : 3 如果 Bessie 引用她的第三篇论文,引用数会变为 (1 ,100 ,3 ,3 )。上文中提到,这一引用数的 h 指数为 3 。
过了8个样例,还是WA了。
如果只需要求h指数,可以先排序,然后枚举就行。
对于多出来的L次引用,应该加在哪里呢?
显然要加载引用次数不少于h的文章中。
那么如何求写完综述之后的新的h指数呢?
对于新指数h,假设已知,推测引用次数不发生改变之前需要满足的条件。
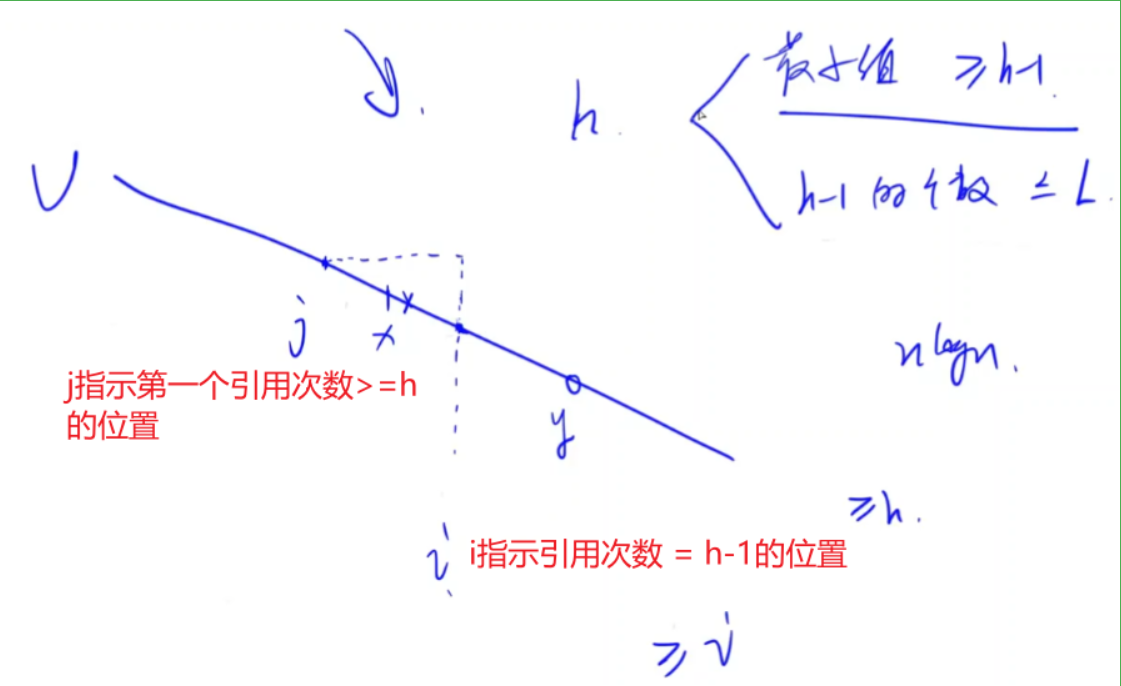
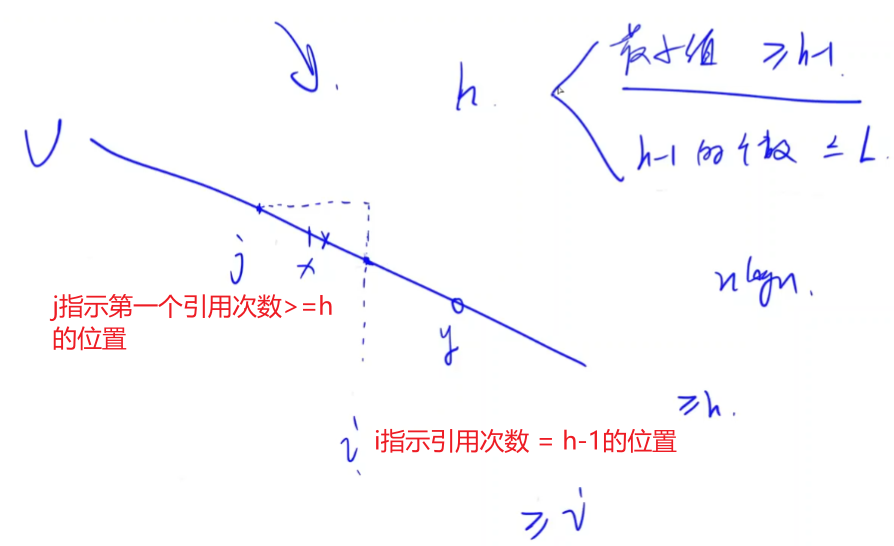
对于满足引用次数不少于新 h 的这些论文,必须满足引用最小值 >= h-1,而且引用次数为h-1的论文数 <= L。
然后就可以根据上面的两个条件对枚举出来的指数h进行判断,找出最大的指数h。
采用双指针进行枚举,指针i枚举指数h,然后指针j枚举第一个满足引用次数 >= h的论文的位置。
要求的是最大的满足条件的h指数,所以i从1开始枚举。(比h小的数都满足条件)
h-1的个数除了可以用双指针求解,也可以用一个大数组记录每个引用量的论文数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <algorithm> using namespace std ;const int N = 1e5 +5 ;int q[N],n,l;int main () cin >> n >> l; for (int i = 1 ;i <= n;i ++) cin >> q[i]; sort(q + 1 ,q + n + 1 ,greater<int >()); int res = 0 ; for (int i = 1 ,j = n;i <= n;i ++){ while (j && q[j] < i) j --; if (q[i] >= i-1 && i - j <= l) res = i; } cout << res << '\n' ; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 为了提高健康水平,奶牛们开始进行体操训练了! 农夫约翰选定了他最喜爱的奶牛 Bessie 来执教其他 N 头奶牛,同时评估她们学习不同的体操技术的进度。 K 次训练课的每一次,Bessie 都会根据 N 头奶牛的表现给她们进行排名。 之后,她对这些排名的一致性产生了好奇。 称一对不同的奶牛是一致的,当且仅当其中一头奶牛在每次训练课中都表现得都比另一头要好。 请帮助 Bessie 计算一致的奶牛的对数。 输入格式 输入的第一行包含两个正整数 K 和 N。 以下 K 行每行包含整数 1 …N 的某种排列,表示奶牛们的排名(奶牛们用编号 1 …N 进行区分)。 如果在某一行中 A 出现在 B 之前,表示奶牛 A 表现得比奶牛 B 要好。 输出格式 输出一行,包含一致的奶牛的对数。 数据范围 1 ≤K≤10 ,1 ≤N≤20 输入样例: 3 4 4 1 2 3 4 1 3 2 4 2 1 3 输出样例: 4 样例解释 一致的奶牛对为 (1 ,4 )、(2 ,4 )、(3 ,4 )、(1 ,3 )。
我的暴力代码,比较麻烦。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> #include <algorithm> using namespace std ;const int K = 11 ,N = 21 ;int n,m,q[K][N];int main () cin >> n >> m; for (int i = 1 ;i <= n;i ++){ int a; for (int j = 1 ;j <= m;j ++){ cin >> a; q[i][a] = j; } } int res = 0 ; for (int i = 1 ;i <= m;i ++){ for (int j = 1 ;j <= m && j != i;j ++){ bool tag = q[1 ][i] < q[1 ][j]; bool flag = true ; for (int k = 2 ;k <= n;k ++){ if (tag && q[k][i] > q[k][j] || !tag && q[k][i] < q[k][j]){ flag = false ; break ; } } if (flag) res ++; } } cout << res; return 0 ; }
暴力做法二,参考大佬做法,时间差不多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <algorithm> using namespace std ;const int N = 22 ;int q[N],f[N][N],n,m;int main () cin >> n >> m; for (int i = 1 ;i <= n;i ++){ for (int j = 1 ;j <= m;j ++) cin >> q[j]; for (int j = 1 ;j < m;j ++){ for (int k = j + 1 ;k <= m;k ++) f[q[j]][q[k]] ++; } } int res = 0 ; for (int i = 1 ;i <= m;i ++){ for (int j = 1 ;j <= m;j ++){ if (f[i][j] == n) res ++; } } cout << res << '\n' ; return 0 ; }